Privacy by Design
How PAICE Achieves Privacy Compliance
📢 Scoring Update (January 2026): This post references the original 0-100 scoring scale. PAICE now uses a 0-1000 point scale for improved granularity. A score of 72 in this post would now display as 720. See PAICE Score™ Changes: What's New in January 2026 for complete details.
This week PAICE.work debuted at the DevLearn conference in Las Vegas. Here's our response to one of the most common first questions/objections we receive: How do you handle Privacy and Regulatory Compliance around that?
When building an assessment platform that measures People + AI collaboration, we faced a fundamental choice: build privacy protections after the fact, or architect them into the foundation from day one.
We chose the latter. This is the technical story of how PAICE.work achieves Privacy by Design, and why that matters for GDPR, CCPA, and your trust.
The Privacy-First Architecture Decision
Most web applications follow a familiar pattern:
- Collect user data (cookies, tracking, accounts)
- Store everything in databases
- Add privacy controls later
- Hope compliance teams can retrofit protections
PAICE inverts this model entirely.
We started with a single question: What's the minimum data needed to deliver value? The answer shaped our entire technical architecture.
Why PAICE Doesn't Use Cookies
The Cookie Problem
Traditional assessment platforms use cookies for:
- Session management
- User tracking
- Analytics
- Personalization
- Cross-site identification
Each cookie creates privacy obligations:
- GDPR consent requirements
- CCPA opt-out mechanisms
- Cookie banners and disclosures
- Data retention policies
- Third-party data sharing agreements
PAICE uses zero cookies. Not "minimal cookies." Not "essential cookies only." Zero.
The localStorage + Server-Side Architecture
PAICE uses a hybrid approach combining browser localStorage with server-side anonymization:
// Pseudocode: How PAICE manages sessions
const sessionId = generateRandomSessionId();
localStorage.setItem('paice_session', sessionId); // Cached locally for continuity
// Send to backend for anonymization
await backend.createUser(sessionId); // Returns irreversible user_hash
// No cookies = No cross-site tracking
// No cookies = No third-party data sharing
// No cookies = No consent banners needed
Why this matters:
| Cookies | localStorage + Server Hash |
|---|---|
| Sent with every HTTP request | Session ID sent only when needed |
| Accessible to third parties | Domain-isolated, server-anonymized |
| Requires consent banners | No consent required |
| Enables cross-site tracking | Cannot track across sites |
| Subject to GDPR Article 5 | Anonymized server-side (Recital 26) |
Technical Implementation
When you start a PAICE assessment:
- Browser generates temporary session ID (client-side random string)
- Session ID sent to backend to create anonymous user hash
- Backend generates cryptographic hash (session ID + random salt)
- User hash and session stored in MongoDB (anonymized, irreversible)
- Assessment proceeds with server-side conversation processing
- Scores calculated and stored in database (linked to anonymous hash)
- Session ID cached in localStorage for continuity during assessment
Result: Your assessment data is anonymized server-side through one-way hashing before storage.
Anonymization at Capture: The GDPR Recital 26 Strategy
What is Recital 26?
GDPR Recital 26 states:
"The principles of data protection should therefore not apply to anonymous information, namely information which does not relate to an identified or identifiable natural person..."
Translation: If data is truly anonymous from the moment of collection, GDPR doesn't apply.
How PAICE Achieves This
Traditional approach (GDPR applies):
User → Identifiable Data → Database → Anonymize Later
PAICE approach (GDPR doesn't apply):
User → One-Way Hash → Anonymous Data → Database
The Technical Details
User and Session Identifiers:
# Actual backend implementation (simplified)
async def create_user(session_id: str) -> str:
# Generate cryptographic salt (32 random bytes)
salt = secrets.token_hex(16)
# Create one-way hash
user_hash = hashlib.sha256(f"{session_id}{salt}".encode()).hexdigest()
# Store user_hash in MongoDB
await db.users.insert_one({
"user_hash": user_hash,
"created_at": datetime.utcnow()
})
# Salt is never stored - hash cannot be reversed
return user_hash
What gets stored in MongoDB:
- Anonymous user_hash (SHA-256, irreversible)
- Session identifiers (linked to user_hash)
- Assessment scores (linked to session)
- Timestamps (for data retention)
What never gets stored (in production):
- Conversation text (turn logging disabled in production)
- Prompts or responses (discarded after processing in production)
- Work task details (never captured)
- Personal information (never requested)
- Original session ID salt (makes hash irreversible)
Note: Turn logging can be enabled in development/test environments via TURN_LOGGING_ENABLED for testing and debugging purposes, but this is always disabled in production by environmental variable policy, not by system code.
Why This Matters for Compliance
Because PAICE operates on anonymous data as defined in GDPR Recital 26, the assessment engine lies outside the scope of GDPR.
This isn't a loophole, it's intentional architectural design:
- No personal data = No GDPR obligations
- No identifiable information = No re-identification risk
- No conversation storage = No data breach exposure
The Conversation Processing Model
Server-Side Processing with Privacy Safeguards
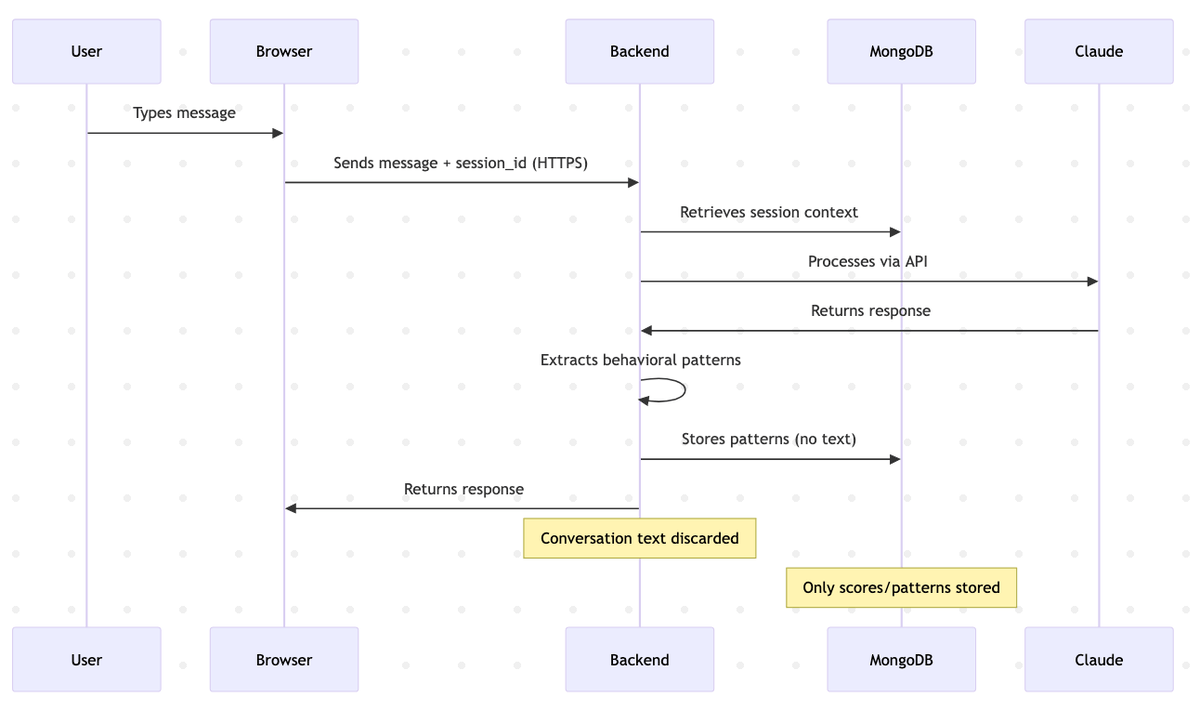
When you interact with PAICE's AI during assessment:
sequenceDiagram
participant User
participant Browser
participant Backend
participant MongoDB
participant Claude
User->>Browser: Types message
Browser->>Backend: Sends message + session_id (HTTPS)
Backend->>MongoDB: Retrieves session context
Backend->>Claude: Processes via API
Claude->>Backend: Returns response
Backend->>Backend: Extracts behavioral patterns
Backend->>MongoDB: Stores patterns (no text)
Backend->>Browser: Returns response
Note over Backend: Conversation text discarded
Note over MongoDB: Only scores/patterns stored
Key points:
- Conversation processed server-side (in memory, not written to disk)
- Behavioral patterns extracted (verification habits, iteration quality, etc.)
- Text immediately discarded (no conversation logs in database)
- Only numeric scores stored (linked to anonymous user_hash)
- Turn logging disabled (configured as server-level policy)
What Gets Extracted vs. Stored
Extracted during assessment (transient):
- Prompt clarity patterns
- Verification behavior
- Iteration quality
- Error detection capability
- Bias awareness signals
Stored after assessment (permanent):
- PAICE Index score (0-100)
- Five dimension scores (0-100 each)
- Numeric sub-parameters (PAICE-proprietary)
- Tier classification
- Timestamp (rounded)
- Anonymous session hash
Never stored:
- Your actual prompts
- AI's actual responses
- Your work task details
- Proprietary information
- Personal identifiers
The Optional Email Separation
Two Isolated Collections in MongoDB
If you choose to provide an email address for follow-up (before or after assessment):
MongoDB Collections:
├─ assessments (scores, user_hash, session_id)
├─ captured_emails (email, session_id, timestamp)
└─ users (user_hash, created_at)
Connection: session_id links email to scores
Anonymization: user_hash prevents re-identification
Technical implementation:
- Separate MongoDB collections
- session_id links email to assessment (for results delivery)
- user_hash prevents correlation across sessions
- Email stored only with explicit consent (GDPR Article 6(1)(a))
- Unique constraints prevent duplicate emails
Why This Design?
Scenario 1: Data breach in MongoDB
- Attacker gets: Anonymous user_hashes, session_ids, scores, emails
- Attacker cannot get: Original session salts (never stored), conversation text (not stored in production)
- Impact: Limited - user_hashes are irreversible, no way to re-identify users across sessions
Scenario 2: Email correlation attempt
- Attacker has: Email + session_id + user_hash
- Attacker cannot: Link user_hash to other sessions (different salt each time)
- Result: Each assessment is isolated, no cross-session tracking possible
Scenario 3: Subpoena or legal request
- We can provide: Scores for a specific session_id (if email provided)
- We cannot provide: All assessments by a user (user_hash changes each session)
- Result: Single-session data only, no user history reconstruction
CCPA Compliance Through Minimal Collection
California Consumer Privacy Act (CCPA) Requirements
CCPA grants California residents rights to:
- Know what personal information is collected
- Delete personal information
- Opt-out of sale of personal information
- Non-discrimination for exercising rights
How PAICE Complies
1. Right to Know: We collect:
- Anonymous assessment scores (if you save them)
- Email address (if you provide it)
- Basic web analytics (anonymized)
That's it. No hidden data collection.
2. Right to Delete:
// Pseudocode: PAICE deletion process
async function deleteUserData(email) {
// Delete email from contact system
await emailDB.delete(email);
// Assessment scores are already anonymous
// Cannot be linked back to user
// No deletion needed (already private)
return { status: 'deleted' };
}
3. Right to Opt-Out of Sale: We don't sell data. Period. This isn't a compliance checkbox, it's a business model decision. PAICE's revenue hinges on organizational assessments, not data monetization.
4. Non-Discrimination: All features available regardless of privacy choices. Declining to provide email doesn't limit assessment experience or scoring access. We do offer additional insights, personalized guidance, and sharing options that are only unlocked by providing a valid email. And while these may be valuable, they are add-ons, not our core offering.
Security Architecture: Defense in Depth
Encryption Everywhere
Data in transit:
- TLS 1.3 for all connections
- HTTPS enforced (no HTTP fallback)
- Certificate pinning for API calls
- Perfect forward secrecy
Data at rest:
- Encrypted database storage
- Encrypted backups
- Key rotation policies
- Hardware security modules (HSM) for key management
Access Controls
Who can access what:
| Role | Assessment Data | Email Data | Aggregate Analytics |
|---|---|---|---|
| User | Own scores only | Own email only | No access |
| PAICE Engineers | Anonymous patterns | No access | Yes (anonymized) |
| PAICE Admins | No individual access | Support requests only | Yes (anonymized) |
| Third Parties | Never | Never | Never |
Audit Logging
Every data access is logged:
// Pseudocode: PAICE audit log
{
timestamp: "2025-11-19T10:30:00Z",
action: "score_retrieval",
actor: "user_hash_abc123",
resource: "session_hash_xyz789",
result: "success",
ip_hash: "hashed_ip_address"
}
Logs are:
- Immutable (append-only)
- Encrypted
- Retained for 90 days
- Reviewed monthly
- Available for compliance audits
Agentic Browser Detection: Protecting Assessment Integrity
The Challenge
Automated browsers (Puppeteer, Selenium, etc.) could:
- Take assessments at scale
- Game scoring algorithms
- Compromise measurement validity
The Privacy-First Solution
PAICE detects agentic browsers without invasive tracking:
// Pseudocode: Non-invasive detection
function detectAgenticBrowser() {
// Check for automation signals
const signals = {
webdriver: navigator.webdriver,
plugins: navigator.plugins.length,
languages: navigator.languages.length,
// ... other non-invasive checks
};
// No fingerprinting
// No tracking
// No personal data collection
return calculateRiskScore(signals);
}
What we DON'T do:
- Canvas fingerprinting
- Font enumeration
- WebGL fingerprinting
- Battery status tracking
- Device motion tracking
What we DO:
- Check for automation flags
- Analyze interaction patterns
- Detect impossible timing
- Verify human-like behavior
Result: Bots blocked, humans untracked.
For technical details, see our blog post: Protecting PAICE: Our Agentic Browser Detection Strategy
Compliance Certifications & Audits
Current Status
GDPR Compliance:
- ✅ Privacy by Design architecture
- ✅ Anonymization at capture (Recital 26)
- ✅ Right to deletion
- ✅ Right to access
- ✅ Right to portability
- ✅ Minimal data collection
- ✅ No cookies requiring consent
CCPA Compliance:
- ✅ Transparent data practices
- ✅ Right to know
- ✅ Right to delete
- ✅ No data sales
- ✅ Non-discrimination
Planned Certifications:
- SOC 2 Type II (2026)
- ISO/IEC 27001 (2026)
- ISO/IEC 42001 (AI Management System, 2027)
Independent Audits
2026 Roadmap:
- Privacy impact assessment (Q1)
- External security audit (Q2)
- Penetration testing (Q3)
- SOC 2 Type II audit (Q4)
Transparency commitment: All audit results published (with sensitive details redacted).
What This Means for You
As an Individual User
Your privacy is protected by architecture, not policy:
- No cookies tracking you
- No conversation logs (in production)
- No identifiable data (anonymized via one-way hashing)
- No data sales
- No surveillance
You control your data:
- Assessment data anonymized server-side before storage
- Email is optional and separate
- Deletion is immediate and complete
- Export is available anytime
As an Organization
Defensible privacy for your employees:
- No GDPR consent requirements for assessment
- No CCPA opt-out mechanisms needed
- No data breach exposure (data already anonymous)
- No vendor risk (we don't have identifiable data)
Compliance-ready architecture:
- Aligns with SOC 2 Type II principles
- Meets ISO/IEC 27001 standards
- Supports ISO/IEC 42001 (AI management)
- Provides audit trail for regulators
The Technical Trade-offs
What We Gave Up
Traditional features we can't offer:
- Persistent user accounts (by design)
- Cross-device sync (requires identification)
- Personalized dashboards (requires tracking)
- Usage analytics (requires monitoring)
Why we gave them up: Because privacy isn't negotiable.
What We Gained
Trust through transparency:
- No hidden data collection
- No surprise privacy policy changes
- No "we take privacy seriously" platitudes
- Actual architectural privacy
Compliance through design:
- GDPR compliance by default
- CCPA compliance by default
- No retrofitting privacy controls
- No compliance debt
Security through minimalism:
- Less data = Less attack surface
- No data = No breach impact
- Anonymous data = No re-identification risk
Frequently Asked Questions
Q: If you don't store conversations, how do you improve the assessment?
A: We store anonymized behavioral patterns (e.g., "users who verify sources score higher"), not conversation text. This gives us improvement signals without privacy compromise.
Q: What if I want to delete my data?
A: Contact us and we'll delete your email (if provided) within 30 days (GDPR) or 45 days (CCPA). Assessment scores are already anonymous and cannot be linked back to you.
Q: Can law enforcement request my assessment data?
A: They can request, but we cannot provide identifiable data because we don't have it. Anonymous scores cannot be linked to individuals.
Q: How do I know you're not secretly storing conversations?
A:
- Our architecture is documented (this post)
- Our code is auditable (request access for security research)
- Our infrastructure is logged (audit trail available)
- Our incentives align (we're a PBC, mission over profit)
Q: What about Anthropic's data retention?
A: Your conversation is processed through Anthropic's Claude API. Anthropic may retain data according to their Commercial Terms (currently 30 days). We chose Anthropic specifically for their privacy commitment. We don't control their practices, but we chose the most privacy-respecting frontier AI provider available. In the future, we plan include other providers as well, including a possible Proton Lumo option. Tell us if that's important to you, so we can prioritize it appropriately on our roadmap.
Q: Will you add user accounts in the future?
A: Yes, in accordance with privacy-by-design principles. Any account system would be:
- Optional (anonymous assessment remains default)
- Minimal (only data needed for feature)
- Isolated (separate from assessment data)
- Deletable (complete removal on request)
The Bottom Line
Privacy by Design isn't a marketing claim, it's an architectural decision.
PAICE achieves GDPR and CCPA compliance not through policies and consent forms, but through fundamental design choices:
- No cookies = No tracking
- localStorage = Session continuity (data anonymized server-side)
- Anonymization at capture = No personal data
- Conversation discarding = No text retention
- Email isolation = No correlation risk
The result: An assessment platform where privacy isn't an afterthought, it's the foundation.
Want to see it in action? Take the free assessment at paice.work and experience privacy-first measurement.
Have technical questions? Read our complete Privacy Policy or contact us.
Building something similar? We're happy to share our privacy architecture approach. It's hard, but it's not that hard, and it's very worth doing.
This post describes PAICE's privacy architecture as of November 2025. We'll provide updates as our systems evolve and audits are conducted, always maintaining our Privacy by Design commitment.
Recommended Reading
📖 Privacy & Security:
- Your Data, Your Privacy: How PAICE Handles Your Information - User-friendly privacy overview
- Protecting PAICE: Our Agentic Browser Detection Strategy - Security without surveillance
📖 Technical Architecture:
- Why Claude? And Why PAICE Is Designed to Work with Any AI Model - Model selection and architecture
- We're Official! PAICE.work PBC - Our commitment to mission over profit
Curious but short on time?
Take the 3-minute PAICE Pulse — a quick confidence check that maps how you see your own AI collaboration posture. No login required.